近年来,生成式人工智能(AI)凭借其深度学习架构迅速发展,展示了对复杂语言结构、上下文甚至图像的非凡理解。这种进化不仅扩大了人工智能的视野,而且在包括医疗保健在内的各个领域开辟了新的可能性。生成式人工智能模型在医疗领域的整合,促使越来越多的研究集中在其诊断能力上。在医疗诊断中,生成式人工智能模型在处理大量医学文献和患者信息方面的准确性、速度和效率表现出了非凡的价值。 近日,杂志npj Digital Medicine上发表了一篇题为“A systematic review and meta-analysis of diagnostic performance comparison between generative AI and physicians”的文章。作者对医疗保健中生成式人工智能模型的诊断能力进行全面的荟萃分析,然后将其与医生的诊断表现进行比较。结果显示,生成式人工智能模型的汇总准确率为52.1%。一些生成式AI模型显示出与非专家医生相当的性能,但总体上显著低于专家医生(准确率差异:15.8%)。该分析旨在为该领域未来的研究和实际应用提供基础参考,最终促进人工智能辅助诊断在医疗保健领域的发展。
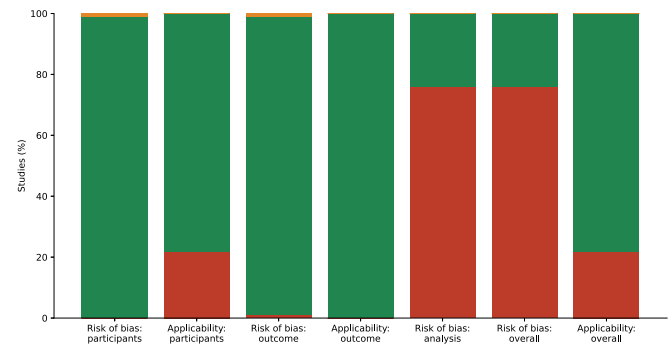
图片来源:npj Digital Medicine 主要内容 荟萃分析研究概述 作者经过筛选最终选择了83个研究进行荟萃分析。研究中评估模型最多的为GPT-4和GPT-3.5,其他还包括GPT-4V、PaLM2、Llama 2、Prometheus、Claude 3 Opus、Gemini 1.5 Pro等模型。该综述涵盖了广泛的医学专业,其中全科医学是最常见的,其他专业还包括放射学、眼科、急诊医学、神经病学、皮肤病学、耳鼻喉科和精神病学等。 偏倚风险评估工具(PROBAST)的评估结果显示,63/83(76%)的研究存在高偏倚风险,20/83(24%)的研究存在低偏倚风险,18/83(22%)的研究具有通用性的风险。65/83(78%)的研究对通用性的风险程度较低(如下图)。主要原因为研究使用小测试集评估模型,以及由于训练数据未知而无法证明外部评估。
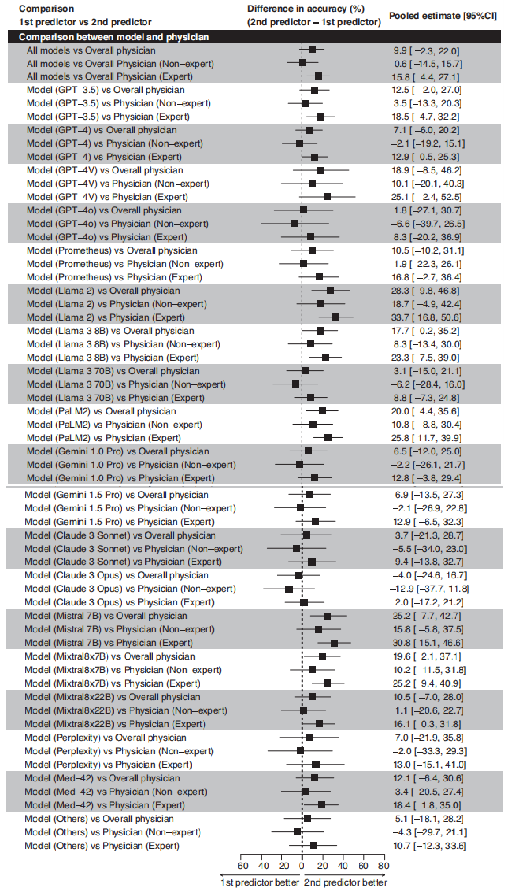
预测模型研究偏倚风险综述。图片来源:npj Digital Medicine 荟萃分析 生成式AI模型的总体准确率为52.1%。荟萃分析显示,生成式人工智能模型总体上与医生(physicians)和非专家医生(non-expert physicians)之间没有显著的性能差异,而生成式人工智能模型总体上明显低于专家医生(expert physicians),准确率差异为15.8% 。 有几个模型,包括GPT-4、GPT- 4o、Llama3 70B、Gemini 1.0 Pro、Gemini 1.5 Pro、Claude 3 Sonnet、Claude 3 Opus和Perplexity,与非专家相比,表现出略高的性能,但差异并不显著。与专家医师相比,GPT-3.5、GPT-4、Llama2、Llama3 8B、PaLM2、Mistral 7B、Mixtral8x7B、Mixtral8x22B、Med-42显著低于专家医师,而GPT-4V、GPT- 4o、Prometheus、Llama 370B、Gemini 1.0 Pro、Gemini 1.5 Pro、Claude 3 Sonnet、Claude 3 Opus、Perplexity与专家相比无显著差异。
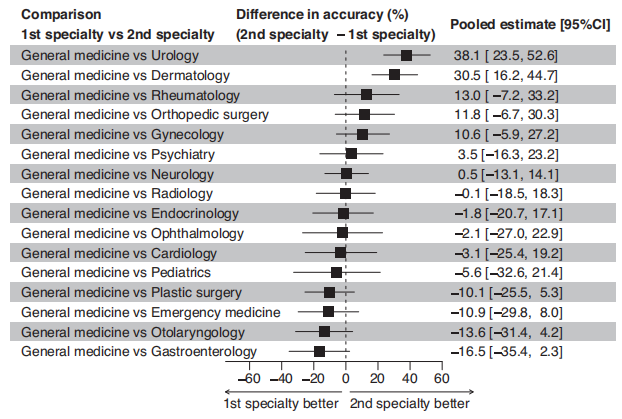
机器模型与医生的表现对比结果。图片来源:npj Digital Medicine 不同专科中的生成AI性能 作者发现,普通医学和各专科之间的表现没有显著差异,除了泌尿科和皮肤科存在显著差异(p值< 0.001)。虽然医学领域模型的准确率略高,但这种差异没有统计学意义。在低偏倚风险亚组的分析中,生成式人工智能模型总体上与医生总体上没有显著的表现差异。作者强调了在大多数医学领域,AI的有效性没有显著差异。
不同专科中的生成AI性能。图片来源:npj Digital Medicine 生成式人工智能在医疗诊断中的能力和局限性 本荟萃分析提供了对生成式人工智能在医疗诊断中的能力和局限性的细致理解。生成式人工智能模型,特别是像GPT-4、GPT- 4o、Llama3 70B、Gemini 1.0 Pro、Gemini 1.5 Pro、Claude 3 Sonnet、Claude 3 Opus和Perplexity这样的高级迭代,有望帮助诊断。生成式人工智能模型的总体中等准确率为52%,目前还不能可靠地替代专家医生,但在非专家场景中可以作为有价值的辅助工具,也可以作为医疗培训生的教育工具。 研究结果还强调了在模型开发方面持续进步和专业化的必要性,以及严格的、外部验证的研究,以克服普遍存在的高偏见风险,并确保生成人工智能有效地融入临床实践。随着该领域的发展,生成式人工智能模型和医疗专业人员都必须不断学习和适应,同时还必须致力于透明度和严格的研究标准。这种方法对于利用生成式人工智能模型的潜力来加强医疗保健服务和医学教育,同时防范其局限性和偏见至关重要。 总结与讨论 在这篇系统综述和荟萃分析中,作者分析了生成式人工智能和医生的诊断表现。该研究涵盖了各种人工智能模型和医学专业,其中GPT-4模型评估最多。荟萃分析显示,生成式人工智能模型的汇总准确率为52.1%。一些生成式AI模型显示出与非专家医生相当的性能,但总体上明显低于专家医生(准确率差异:15.8%)。在大多数医学领域,有效性没有显著差异。 总之,生成式人工智能展示了有前途的诊断能力,其准确性因模型而异。虽然它还没有达到专家水平的可靠性,但这些发现表明,在适当了解其局限性的情况下实施,有可能加强医疗保健服务和医学教育。 |

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号