在癌症转移之前发现癌症是成功抗癌的关键。最近,无细胞DNA(cfDNA)因其在早期癌症检测中的实用性而受到关注。具体而言,cfDNA甲基化已被证明是一种非常有前景的特征,不仅能够检测癌症,而且能够定位其起源组织(TOO)。尽管它前景广阔,基于cfDNA的癌症检测面临着一些主要挑战:(1)早期癌症患者血液中肿瘤cfDNA的比例可能很低,(2)不同癌症类型、亚型、阶段和病因的cfDNA异常特征是异质的;(3)与疾病的多样性和患者群体(年龄、性别、种族和共病)相比,目前可用的样本量较小,尤其是对于泛癌检测而言。 为了应对cfDNA中肿瘤比例(tumor fraction)极低的挑战,甲基化组检测可以利用血液中尽可能多的cfDNA片段,而不似传统深度测序方法只捕获所有肿瘤cfDNA片段的一小部分。为了解决癌症的分子异质性,基于甲基化组的检测可以覆盖不同癌症类型和病因的甲基化标记的广阔前景。为了应对目前可用样本量有限的挑战,基于甲基化组的测试可以随着训练队列的增长学习和利用新的重要标志物。尽管cfDNA甲基化组分析具有优势,但常用的全基因组甲基化测序(WGBS)成本太高,无法用于临床应用。 近日,来自顶尖学府UCLA的研究团队在Nature Communications上发表了一篇题为“Cost-effective methylome sequencing of cellfree DNA for accurately detecting and locating cancer”的文章,在这篇文章,研究团队提出了一个完整的实验和计算系统,用于准确和相对便宜的癌症检测。它包括(1)一种用于cfDNA全基因组甲基化分析的成本效益高的实验分析,称为无细胞DNA甲基化组测序(cfMethyl-Seq),以及(2)一种提取四种类型的cfDNA甲基化特征(癌症特异性和组织特异性高甲基化和低甲基化标记)的计算方法,并执行集成学习以检测和定位癌症。结果显示:(1)检测癌症:总体AUC为0.974,总体敏感性为80.7%,特异性为97.9%。单个癌症类型的敏感性范围为75.9%至92.3%。(2)定位癌症:肿瘤TOO预测的准确率为89.1%。研究团队同时还进行了广泛的验证,例如跨批次验证、跨来源验证、年龄匹配验证、以及独立验证,以确认此方法的稳健性。
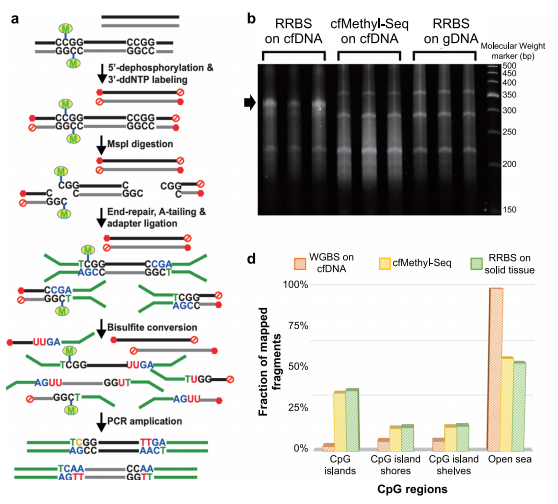
图片来源:Nature communications 主要内容 低成本的无细胞DNA甲基化组测序(cfMethyl-Seq) 研究团队开发了cfMethyl-Seq技术,以解决低成本分析cfDNA全基因组甲基化的挑战。传统的RRBS方法,也可以从完整的基因组DNA丰富CpG富集区。 cfMethyl-Seq过程如下图所示,基于cfDNA构建的cfMethyl-Seq文库显示特征条带,长度为68bp,135 bp和203 bp(图b)。将cfMethyl Seq文库与cfDNA WGBS文库以及实体组织RRBS文库进行了比较。34.11%、12.38%和13.14%的cfMethyl-Seq读数来自CpG island、shore和shelf地区,而传统RRBS读数分别为33.65%、13.35%和14.04%(图d)。对于WGBS cfDNA库,只有2.66%的读取来自CpG岛,但大多数(88.32%)来自无信息的“open sea”区域。也就是说,cfMethyl Seq在CpG岛上比WGBS富集12.8倍。
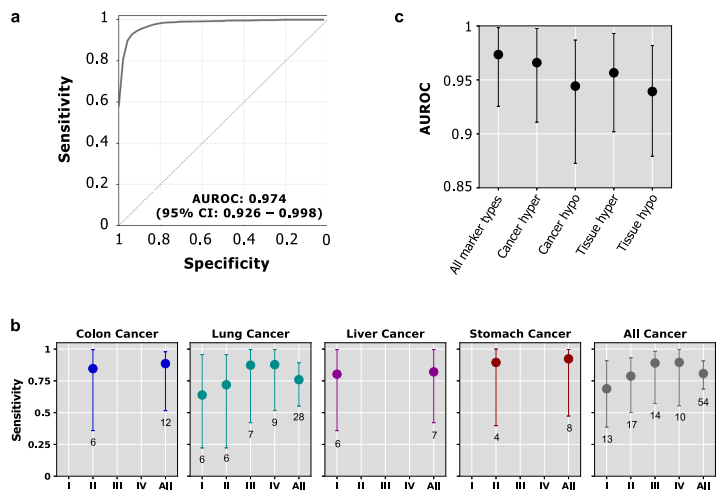
cfMethyl-Seq 检测技术。图片来源:Nature communications 用于癌症检测和组织起源预测的甲基化标志物的发现 研究团队生成了用于标志物发现的328个实体组织的RRBS数据,包括131对实体肿瘤及其邻近的正常组织,包括结肠癌(19对)、肝癌(53对)、肺癌(44对)和胃癌(15对)。确定了实体肿瘤及其邻近正常组织之间存在显著差异的癌症特异性标记物。此外要求癌症特异性标记物在实体肿瘤和30个参考非癌症个体的cfDNA之间具有差异甲基化。在10次运行中,平均获得了23748个癌症特异性高甲基化标记和28197个癌症特异性低甲基化标记用于癌症检测。 为了预测TOO,还确定了任何两种实体肿瘤类型之间以及实体肿瘤和30例参考非癌血浆样本之间显著不同的标记物。在10次运行中,为了预测癌症TOO,研究团队平均获得30474个肿瘤特异性高甲基化和33890个肿瘤特异性低甲基化标记。 组织特异性cfDNA有助于检测癌症和预测其TOO。研究团队确定了任何两种实体正常组织之间存在显著差异的标记,包括7547个组织特异性高甲基化和7212个组织特异性低甲基化标记物,可以区分成对的组织类型。 癌症检测的性能 408份cfDNA样本的cfMethyl-Seq数据采集自191名非癌症患者和217名癌症患者(分别来自结肠癌、肝癌、肺癌和胃癌患者的49、30、106、32名)。从217个癌症cfDNA样本中,随机选择75%作为训练数据,25%作为测试数据;从191个非癌cfDNA样本中随机选择了25%作为测试数据,在剩余的75%中,随机保留了30个仅用于标志物发现的非癌cfDNA样本,并将剩余的非癌cfDNA样本用作训练数据。 标志物类型的排名从高到低依次为癌症特异性高甲基化标志物(0.966)、组织高甲基化标志物(0.957)、癌症特异性低甲基化标志物(0.944)、组织低甲基化标志物(0.939)。通过整合四种标记物类型,癌症检测总体模型的AUROC为0.974,在97.9%的特异性下,敏感性为80.7%(图a)。对于早期癌症(I期和II期)样本,整体模型的AUROC为0.964,敏感性为74.5%,特异性为97.9%。当将这些结果分解为各个癌症类型和阶段时(图b),在所有情况下的敏感性均达到或超过63%。
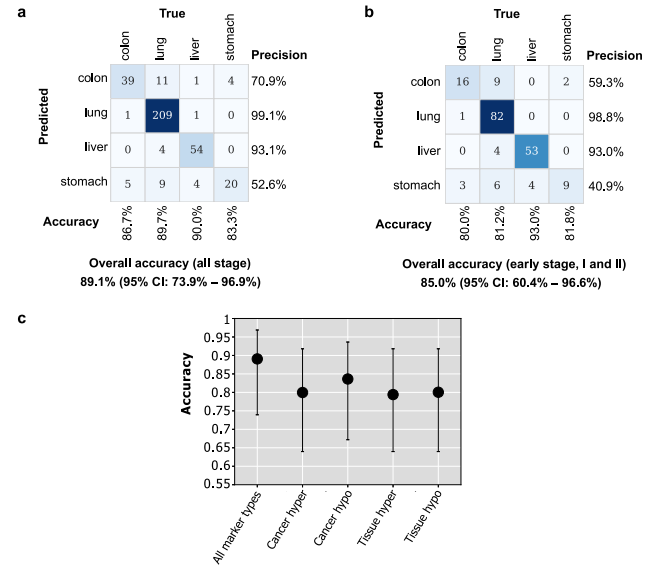
用于癌症检测的集成模型的性能。图片来源:Nature communications TOO预测的性能 使用相同的验证策略来评估癌症样本的TOO预测性能。癌症特异性高甲基化标记的平均准确率为80.0%,癌症特异性低甲基化标记为83.6%,组织特异性高甲化标记为79.4%,组织特异性低甲基化标记物为80.0%。通过整合四种标记类型,TOO预测集成模型在所有阶段的平均准确率达到89.1%。对于早期癌症患者,模型平均准确率为85.0%。,所有阶段的结肠癌/肝癌/肺癌/胃癌TOO预测准确率为86.7%/89.7%/90.0%/83.3%(图a),早期预测准确率为80.0%/81.2%/93.0%/81.8%(图b)。
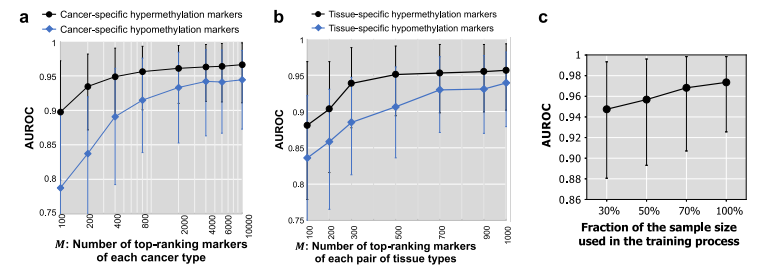
用于癌症TOO预测的集成模型的性能。图片来源:Nature communications 标志物数量和训练样本大小的影响 研究团队研究了甲基化标志物的数量如何影响分类器的性能。对于所有标志物类型,癌症检测的性能(AUROC)随着所用标志物的数量而增加。每种癌症类型有200个肿瘤特异性高甲基化标记物,已经可以达到0.935的AUROC。当标志物数量达到2000后,AUROC的增加趋势减缓(AUROC = 0.961). 进一步研究了训练样本大小如何影响分类器性能。如图c所示,随着增加训练样本的增加,癌症检测模型的平均性能显著提高。这一观察结果也适用于每个标记类型的一级模型。此外,用于癌症检测任务的所有预测模型的性能方差降低。这表明,随着训练规模的增大,模型的性能将有所提高。
标志物数量和训练样本大小对癌症检测性能的影响。图片来源:Nature communications 评估分类器对潜在混杂因素的鲁棒性 为了评估分类器对批次、样品来源和年龄等潜在混杂因素的鲁棒性,研究团队进行了以下额外验证: (1)跨批次验证,其中测试和培训集中的样本来自非重叠批次。跨批次验证的AUROC为0.943,与随机分割验证的AUORC为0.954。这表明分类器对批次效应具有鲁棒性。 (2)跨源验证,即在不同地点采集测试和培训样本集中的样本。当使用来自加州大学洛杉矶分校的样本进行培训,使用来自商业来源的样本进行测试,获得了0.992的AUROC。随机分割验证得出AUROC为0.982,交叉验证得到的AUROC相似。 (3)年龄匹配验证,即仅选择那些分别与训练集和测试集中所有癌症样本的年龄分布相匹配的非癌症样本。平均AUROC为0.948,与随机分割验证的AUROC 0.931相当。分类器对年龄的鲁棒性可能归因于使用来自同一患者的配对肿瘤和相邻正常组织进行标志物选择,因此任何标记的选择都应该是由于肿瘤/正常差异,而不是年龄差异。 (4)独立验证。对于level-1模型,使用癌症特异性低甲基化和高甲基化标记物,分别获得了0.998和0.956的AUROC,证明了标记物和一级分类器的稳健性。组织特异性低甲基化和高甲基化标记物在AUROC分别为0.939和0.882。 上述四个验证表明,癌症检测分类器对潜在的批次效应、不同的样本源、年龄,甚至不同的实验平台(对于1级分类器)都具有鲁棒性。对于癌症TOO预测,没有足够数量的样本进行分析以支持上述验证。 总结与讨论 在这里,研究团队开发了一个集成的实验和计算系统,以解决基于cfDNA的早期癌症检测的主要挑战:即血液中肿瘤负担低,癌症的分子异质性,以及目前可用的训练样本太小,无法准确代表疾病和患者群体的异质性的事实。 这个系统可用于准确和相对便宜的癌症检测。包括(1)一种用于cfDNA全基因组甲基化分析的成本效益高的实验分析,称为无细胞DNA甲基化组序列测定(cfMethyl-Seq),以及(2)一种提取四种类型的cfDNA甲基化特征(癌症特异性和组织特异性高甲基化和低甲基化标记)的计算方法,并执行集成学习以检测和定位癌症。cfMethyl-Seq对CpG富集区域进行甲基化分析并确定了四种类型的甲基化特征,即癌症(组织)特异性高(低)甲基化特征。结果显示:(1)检测癌症:总体AUC为0.974,总体敏感性为80.7%,特异性为97.9%。单个癌症类型的敏感性范围为75.9%至92.3%。(2)定位癌症:肿瘤TOO预测的准确率为89.1%。研究团队进行了广泛的验证,例如跨批次验证、跨来源验证、年龄匹配验证、,以及独立验证,以确认方法的稳健性。结果表明,在个体甲基化特征中,癌症特异性高甲基化在检测癌症方面表现出最高的能力,而癌症特异性低甲基化在TOO预测方面信息最丰富。 最后,数据表明,随着训练样本大小的增加,方法的检测能力继续增加。尽管所有现有的癌症检测研究都受到训练样本大小的限制,但cfMethyl-Seq独特且经济高效地保留了癌症异常的全基因组表观遗传特征,从而允许分类模型随着训练队列的增长学习和利用新的重要特征,并将其范围扩展到其他癌症类型。因此,cfMethyl-Seq可以真正促进癌症检测的大数据方法。 |

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号