相信生信技能树的粉丝对我在2019上半年举行的十余场《我的生信五周年》演讲应该是不陌生了,我入场生物信息学领域时转录组约人民币2万一个样本, 目前均价不到1000。我差不多算是见证了时代的变迁,还仅仅是5年的跨度。相信你一定会感兴趣RNA-seq这10年的变化。 我们在生信菜鸟团公众号举办的每周文献精选活动,菜鸟团一周文献推荐(No.20)广受好评的是大神级的RNA-Seq综述,题目:RNA sequencing: the teenage years ,所以在我们生信技能树VIP交流群也得到了关注。 当时就号召过群友翻译,五天过去了,读研笔记公众号率先完成全部翻译文稿,特发布给所有粉丝,如果是生信技能树铁粉应该是对读研笔记不陌生,他在我们2018的statquest学习交流群脱颖而出。
文献信息
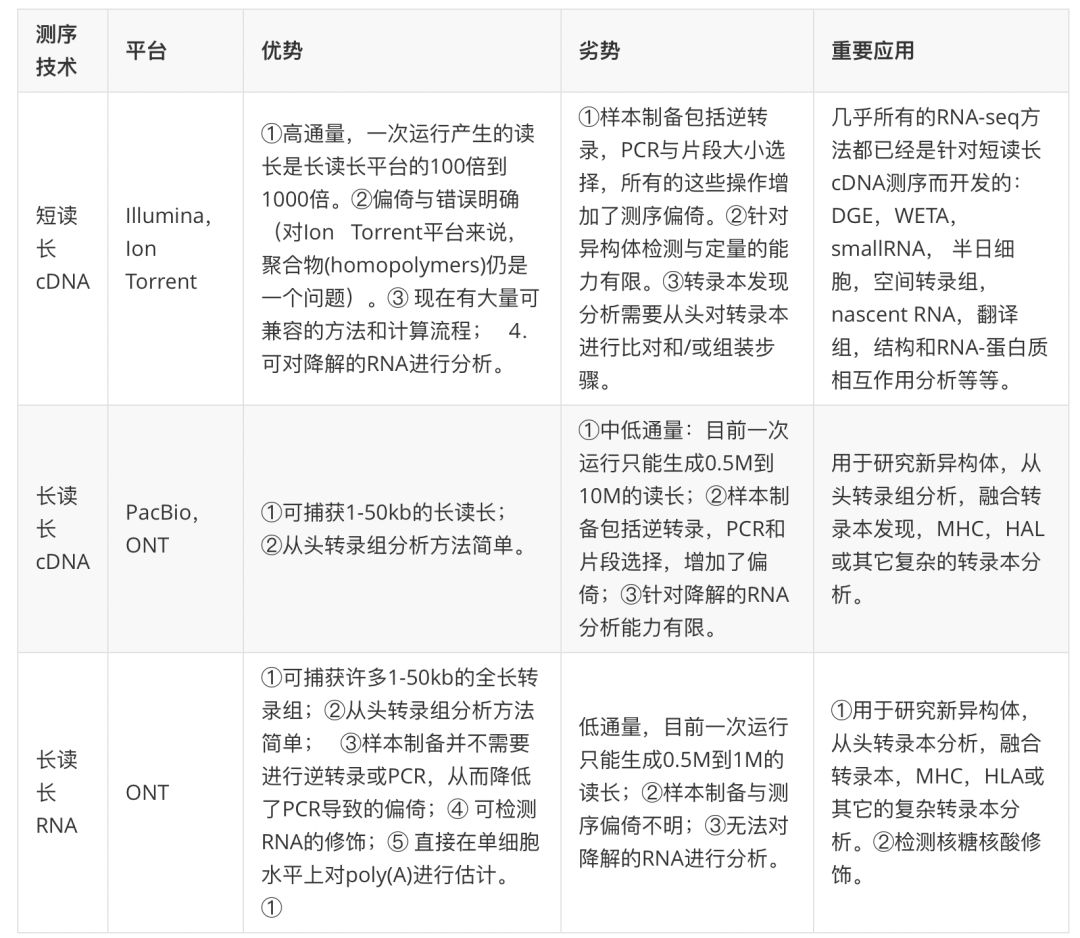
摘要在过去的十年中,RNA测序(RNA-seq)已经成为在全转录组范围内分析差异基因表达和mRNAs差异剪接的重要工具。然而,随着下一代测序技术的发展,RNA-seq技术也在不断发展。现在,RNA-seq用于研究RNA生物学的许多方面,其中包括单细胞基因表达、翻译(翻译组,translatome)和RNA结构(结构组,structurome)。RNA-seq的其它应用也在开发中,例如空间转录学(spatialomics)。加上新的长读长 (long-read,注:在本文中,RNA-seq测序生成的read统一译为“读长“)和直接RNA-seq(direct RNA-seq)技术以及用于数据分析的更好的计算工具的整合,RNA-seq技术的创新有助于人们更全面地理解RNA生物学,例如从何时何地转录发生到控制RNA功能的折叠和分子间相互作用等问题。 前言RNA-seq技术出现于十年之前,自其诞生之日起,RNA-seq就成了研究分子生物学的普遍工具,这项技术几乎构成了我们对基因组功能的认知基础 。RNA-seq中最常用的分析方法就是找出差异基因表达(Differential gene expression, DGE)。从最早的出版期刊开始,DGE分析的基本阶段就未发生实质性的改变。 在实验室中,其标准流程就分为三步: 第一步是构建测序文库,这一步骤包括提取RNA,富集mRNA或清除核糖体RNA,合成 cDNA,加上接头。 第二步,在高通量平台(通常是Illumina平台)上对文库进行测序,每个样本的测序深度为10-30M读长数(读长这里就是前面说的reads)。 第三步是数据分析,具体的工作是:对测序得到的读长进行比对(aligning)和/或组装到转录组上,对这些覆盖了转录组的读长进行过滤,归一化(Normalization),根据统计模型找出那些在不同样本之间有差异的转录本。早期的RNA-seq从大量的实验样本中产生了DGE数据,这充分说明了RNA-seq在广泛的生物体以及系统中的使用,这些生物体包括玉米(Zea mays), 拟南芥(Arabiodopsis thaliana), 酿酒酵母(Saccharomyces cerevisae),小鼠(Mus musculus)以及人类。虽然RNA-seq这个术语经常被用于那些完全不同的方法学方法和/或生物学,但是DGE分析仍然是RNA-seq(补充材料中的表1)的主要应用,并被视为常规研究工具。 RNA-seq的更广泛应用已经促进了我们对生物学多方面的理解 ,例如通过提示mRNA剪接和非编码RNAs和增强子RNAs对基因表达的调控。RNA-seq的应用和进步是由技术发展(湿实验室和计算生物学)驱动的,相对于以前的基因芯片,RNA-seq这种方法对RNA生物学和转录组产生更丰富并且偏见更小的信息。到目前为止,从标准的RNA-seq方法衍生而来的各种RNA-seq方法几乎有100种。Illumina的短读长(short-read)测序平台能对这些由大部分不同方法的RNA-seq构建的文库进行测序,但是最近长读长(long-read)RNA-seq的与直接RNA-seq测序(direct RNA sequencing, dRNA-seq)的进步已经能够解决以前研究人员使用短序列手段无法解决的一些问题。 在这篇综述中,我们首先会介绍一些最基本的短读长RNA-seq中的DGE方法,再将这种基础方法与最近新兴的长读长RNA-seq和dRNA-seq进行比较。我们会介绍短读长测序方法在文库制备方面的进展,以及实验设计和DGE的数据分析方法。随后我们会拓展这些常规的RNA-seq方法,介绍一些单细胞测序和空间转录组学的分析。我们会提供一些案例,介绍RNA-seq在RNA生物学方面的关键应用,包括转录组分析,翻译动力学,RNA结构,RNA-RNA之间相互作用和RNA-蛋白质的相互作用。最后,我们会简单描述一下RNA-seq的未来,以及单细胞和空间RNA-seq方法是否会像DGE分析一样成为常规工具,长读长测序方法是否会取代短读长测序方法。由于篇幅限制,我们无法介绍所有的RNA-seq方法,在这些方法中,值得注意的是非编码转录组学,原核转录组学(prokaryotic transcriptomes)和表观转录组学(epitranscriptome)。 RNA-seq技术的发展历史Illumina的短序列读长测序技术生成了SRA(Short Read Archive)中95%已表达的数据(附件表2)。由于cDNA的短序列读长测序方法几乎是一种常规的方法,因此 我们认为这是一种最基础的 RNA-seq技术,我们先来讨论这种测序主要流程与局限。不过,长读长cDNA测序与dRNA-seq已经兴起,随着研究人员对能提供更丰富转录本水平方面(isoform-level)数据需求增大,这两种新的测序方法有望对常规的短读长测序方法提出挑战(FIG1, TABLE1)。 Table1-短读长与长读长RNA-seq平台
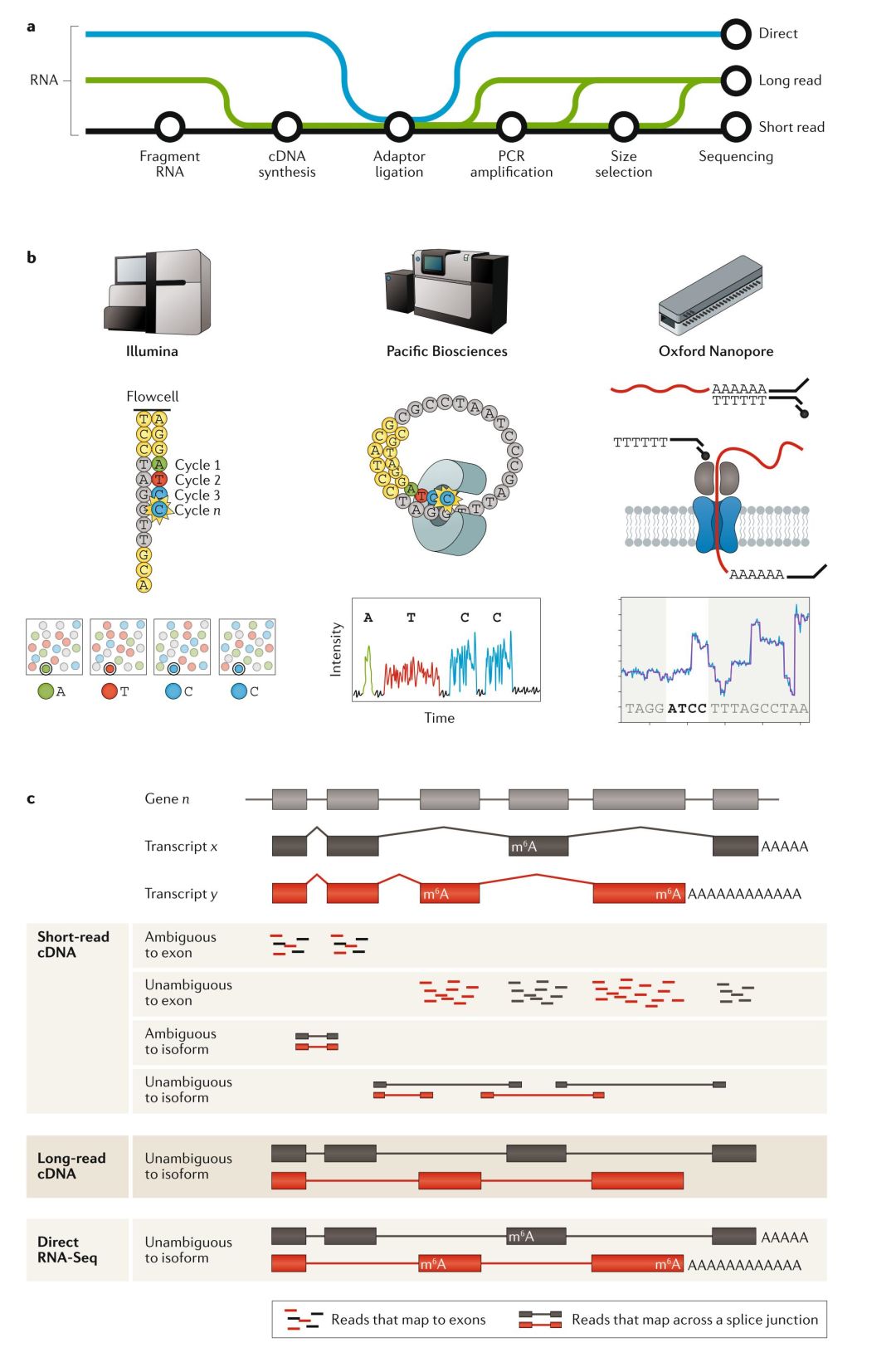
Figure 1-短读长,长读长和直接RNA-seq技术与工作流程
短读长cDNA测序短读长已经成了在整个转录组范围内对基因进行检测和定量的事实方法(de facto method),部分原因是这种方法比芯片成本更低,操作更方便,但是其主要原因还是因为这种方法能生成更全面,更高质量的数据,这种方法能够 对整个转录组中的基因表达水平进行定量。使用Illumina短读长测序平台进行DGE分析的核心步骤包括:RNA提取、cDNA合成、接头连接、PCR扩增、测序和数据分析(FIG1)。在这个过程中,存在打断片段,片段长度选择和基于磁珠的文库纯化这些操作,因此这种方法产生的cDNA片段通常都是在200bp以下。RNA-seq文库的测序读长分配到每个样本上的话,每个样本会测到平均20-30 million条读长(reads)(也就是常说的20-30M条读长),数据经过处理后,使用这些读长对每个基因或转录本进行定量,最后再用统计学方法来统计基因的差异。短读长RNA-seq方法很稳健,并且通过对短读长测序技术的大范围比较发现,这种技术在平台内和平台间的相关性很好。但是,在样本制备和数据分析这两个阶段会引入一些干扰和偏倚。这种局限可能会影响通过实验来解决特定生物学问题的能力,例如准确识别和量化多个异构体中的哪个来源于一个基因。对于研究那些非常长,高度可变的转录本异构的人来说,这种局限表现得尤为明显,例如在人类转录组研究中;人类转录本的长度范围是109bp到186kb,其中50%转录本长度大于2500bp。尽管短读长RNA-seq可以对最长的转录本进行详细的分析,但是涉及的实验方法不能扩展到全转录组分析。其他的偏倚与局限来源于那些大量的计算方法,这些方法包括例如如何处理模糊或多个回贴的读长(multi-mapped reads)。现在出现了一种合成长读长(synthetic long reads)的新方法,这种方法可以实现全长的mRNA测序,并试图解决其中的一些局限。这种方法使用了唯一分子标识符(unique molecular identifiers,UMI)来标记全长的cDNA,在制备短读长RNA文库之前,加入的UMI会随着单个cDNA分子而进行复制。转录本异构体可以在高达4kd的contigs中重建,用于发现异构体和表达分析。但是,对于从根本上解决短读长cDNA测序固有局限的最可能解决方案则是长读长cDNA测序和dRNA-seq测序 。 长读长cDNA测序虽然Illumina测序目前是占主导地位的RNA-seq平台,但PacBio和Oxford Nanopore(ONT)公司都提供了可供选择的长读长技术,能够对完整的单个RNA分子进行单分子水平级的测序。通过消除短RNA-seq测序数据的组装这一步,这些新方法克服了短读长测序方法相关的一些问题。例如,减少了测序读长回贴过程中的歧义,并且可以识别更长的转录本,这样就能获取更完整的异构体多样性信息。这些方法还能降低许多短读长RNA-seq计算工具中关于剪接连接的假阳性。 PacBio的Iso-Seq技术可以读取最高可达15kb的转录本的全长cDNA,这就有利于发现大量以前未注释的转录本,并通过检测物种的全长同源序列证实了早期的基因预测。在标准的Iso-Seq操作流程中,高质量的RNA被一个模板切换凝聚力转录酶(a template-switching reverse transcriptase)反转录为全长的cDNA。生成的cDNAs再经过PCR扩增,加入到PacBio的单分子实时(single-molecule, real-time)文库制备系统中。制备好的短转录本序列可以很快地扩散到测序芯片的活性表面,但由于短转录本的测序存在偏倚,因此在对转录本进行测序时,建议选择片段的长度是1到4kb,这样就能在此范围对长转录本和短转录本进行更加均匀地采样。由于PacBio测序方法需要大量的模板,因此需要进行多轮PCR,不过这一操作还需要进行优化,从而降低扩增导至的偏倚。经过PCR的末端修复和PacBio SMRT接头连接后,就可以进行长读长测序了;通过修改测序芯片的上样条件,就可以在这一步骤进一步控制测序片段长度。 ONT cDNA测序方法也能产生全长的转录本读长,甚至还能在单细胞水平上产生该读长。模板转录逆转录酶也在这种方法中用于制备全长cDNA,制备好的cDNA可以选择使用PCR来进行扩增,随后在产物上加上接头,形成测序文库。直接cDNA测序会消除PCR偏倚,从而形成高质量的测序结果;但是,如果使用PCR来制备测序文库的话,需要的RNA数量更少。ONT cDNA测序法尚未报道过在PacBio测序仪上观察到的片段长度偏倚。 这两种长读长cDNA方法都受到标准模板切换逆转录酶使用的限制,这种逆转录酶能用全长RNA以及截短的RNA来生成cDNA。逆转录酶可以将那些只含5ʹ帽子结构的mRNA置换为cDNA,这样的话,那些由于RNA降解,RNA剪接或不完全cDNA合成而生成的短转录本就不会被反转录为cDNA,从而提高数据质量。但是,有报道指出,逆转录酶会对ONT平台的读长产生不良影响。 长读长直接RNA测序前面我们提到了长读长测序方法,这种测序方法与短读长测序平台一样,它们都依赖于将mRNA转换为cDNA。而最近Oxford Nanopore指出,他们的纳米孔测序技术可以直接对RNA进行测序,也就是说,这种测序手段不需要常规测建库过程中的的cDNA的合成和/或PCR扩增操作。这种方法称为dRNA-seq,这种方法就消除了常规建库过程中的偏倚,并且能够保留表观遗传学信息。这种方法可以从RNA直接进行两个接头的连接来制备文库。首先,带有一个oligo(dT)悬臂的双链核酸接头退火并连接到RNA的多聚腺苷酸(PolyA)尾部,随后就是可选(但不推荐的)的逆转录操作,这一步用于提高测序的通量。第二个连接操作就是添加测序接头,这个测序接头上已经提前安装有驱动测序的马达蛋白。文库随后进行MinION测序,其中RNA直接从3ʹpoly(A)尾部向5ʹcap端进行测序。最初的研究表明,dRNA-seq的测序长度过超过1000bp,最大测序长度过超过10kb。与短读长测序相比,这种长读长测序的几个优势在于:长读长测序可以提高对异构体的检测,并且它们还可以用于下方代码poly(A)尾巴的长度,这对于可变poly(A)分析( alternative poly(A) analysis)来说非常重要。Nanopolish-polya这个工具可以对那些用纳米孔测序得到的数据进行分析,计算出poly(A)尾的长度,这就包括基因之间的长度,也包括转录亚型之间的长度。这种分析证实了,保留内含子的转录本比完全剪接的转录本具有略长的poly(A)尾巴。虽然dRNA-seq还处于起步阶段,但是它具有检测RNA碱基修饰的潜力,因此它的应用潜力巨大,尤其是能够对表观遗传学转录进行新的分析。 长读长与短读长技术的比较虽然长读长技术在评估转录本方面比短读长技术有一些明显的优势,但是长读长技术也有一些明显的局限。尤其是与短读长技术相比,长读长技术的测序通量更低,错误率更多。但长读长技术的主要优势在于,它们能够捕获更多的单个转录本,不过这依赖于高质量的RNA文库。总体来说,这些局限影响了那些完全依赖于长读长测序实验的灵敏性(sensitivity)与特异性(specificity)。 长读长测序方法的主要局限就是当前的通量。在Illumina平台上,运行单次的RNA-seq可以生成10E9-10E10条短读长,但是在PacBio和ONT平台上,一次RNA-seq则只能产生10E6-10E7条读长。这种低通量限制了应用长读长测序技术进行实验的规模,并降低了对差异基因表达检测的灵敏性。然而,并非所有的实验都需要高深度测序。对于那些主要研究异构体的发现以及其特征的研究者们来说,测序长度比测序深度更重要。例如1百万个PacBio环形一致性测序(circular consensus-sequencing, CCS)的读长几乎就可以保证产生那些大于1kb的高表达基因的检测,ONT测序技术也是如此。因此,对于那些低到中等水平表达的基因来说,测序深度确实是一个主要问题。当进行同期功能基因组学分析(contemporary functional genomics analysis)大规模的DGE实验时,这种低通量测序技术的局限就会表现得明显。在这些研究中,必须对多个样本组进行分析,每组就是由多个生物学重复构成的,这样就能够实现充分的统计功效来有确认那些在整个转录组水平上发生的精确变化。对于这种需求,长读长技术不太可能取代短读长技术,除非长读长的测序读长的生成量能提高2个数量级。随着全长RNA-seq读长数目的增加,转录本检测的灵敏度将会增加到类似于Illumina平台上的这种水平,并同时具有更高的特异性。与此同时,通过将Illumina 的短读长RNA-Seq与PacBio的长读长Iso-Seq结合(并且可能还与ONT方法结合),可以增加全长RefSeq注释的异构体检测的数量、灵敏性和特异性,同时保留转录本量化的质量。虽然长读长RNA-seq方法目前的实验成本较高,但它们可以检测到短读长方法遗漏的异构体,尤其是那些难以测序但与临床相关的区域,例如高度多态的人类MHC或雄激素受体。 长读长测序平台的第二个主要局限就是其更高的错误率,它比成熟的Illumina测序仪要高出一到两个数量级。长读长测序平台上生成的数据还包含更多的插入-删除错误。虽然这些错误与识别变化(variant calling)有关,但在RNA-seq中,每个碱基都被正确识别并非那么重要而长读长测序的目标是要阐明转录本和异构体(While these error rates are of concern for variant calling, in RNA- seq it is less crucial that every base be called correctly, as the goal is only to disambiguate transcripts and isoforms)。这种错误率对于其应用来说确实是一个值得观注的问题,现在正在解决这一问题。PacBio SMRT测序平台上出现的随机错误通常可以通过使用CCS增加测序深度来进行解决,在这种技术里,cDNA经过长度选择和接头进行环化后,每个分子就可以被多次测序,从而产生长度范围是10-60kb的连续长读长,并且包含许多原始cDNA的拷贝。这些长读长经过数据分析后就被处理为单个cDNA子子读长(subreads),这些子读长被组合后就可以产生一致的序列。分子测序的次数越多,产生的错误率就越低;CCS已经被证明可以将错误率降低到与短读长相当的水平,甚至更低。但是,将更多的这个平台的测序能力用于重新读取相同的分子,就又加剧了其测序通量的问题,因为可以读取的唯一转录本变得更少了。 长读长RNA-seq方法的灵敏度还受到其他几个因素的限制。首先,它们依赖于长RNA分子以全长转录本的形式进行测序,但是要达到这种情况并非总能实现,因为在样品处理和RNA提取过程中RNA会发生降解或剪接。这种情况在短读长RNA-seq中也存在(3ʹ端的偏倚),但这种问题在短读长中是可控的,对于全长转录组分析进行研究的研究者们来说,即使是低水平的RNA降解,也能限制长读长的RNA-seq效果。因此,对于那些即将使用长读长进行测序的研究者来说,需要仔细地对提取的RNA进行质控。其次,中位数的读长长度会进一步受到文库制备中的技术问题与偏倚的限制,例如有些cDNA合成的截断或某些cDNA是由降解的mRNA合成的,最近开发的高效逆转录酶对此有所改进,这些酶有着更高的链特异性,甚至能够产生更多的3ʹ-5ʹ转录本的覆盖。虽然这些酶还未被广泛使用,但是这些高效逆转录酶也提高了结构稳定的RNAs,例如tRNAs的覆盖率,在oligo-dT和全转录组分析(WTA)方法中使用的逆转录酶很难处理这些结构稳定的RNAs。第三,长读长测序平台固有的偏倚(例如长文库分子在测序芯片表面上的低扩散)会降低更长转录本的覆盖率。 长读长方法(使用cDNA或dRNA-seq)解决了用于异构体分析的短读长测序方法中的一个基本问题,即它们的读长长度。长读长方法可以生成从Poly(A)尾部到5ʹcap的跨异构体的全长转录本读长。因此,这些方法使得分析转录本及其异构体成为可能,从而无需从短的读长中重构它们或推断它们的存在;每个测序的读长仅仅代表了它的起始RNA分子。全长cDNA测序或dRNA-seq用于分析DGE的未来应用将依赖于PacBio和ONT技术的更高通量。长读长RNA-seq分析正被研究者们迅速采用,并与深度短读长RNA-seq数据结合起来,用于更全面的分析,这非常类似于基因组组装所采取的混合方法。随着时间的推移,长读长和dRNA-seq方法可能会用于证明已经鉴定的基因和转录本的列表,即使在研究很透的生物中,对于基因和转录本的研究也还远远不够。随着方法的成熟,以及测序通量的增加,差异转录本分析将会成为常规方法。合成长读长RNA-seq或其它技术的发展将对这个领域产生什么样的影响,还有待观察。然而从目前来看,Illumina短读长RNA-seq依然占据了主导地位,在这篇综述的剩下部分中我们将会集中讨论短读长测序。 改良RNA-seq建库方法RNA-seq最初用于分析多聚腺苷酸化的转录本,使用的方法源于早期的表达序列标签(expressed-sequence tag)和芯片研究。然而,下一代测序的使用指出了这些方法的局限性,而这些局限性在芯片数据中并不明显。因此,在RNA-seq首次报道后不久,就有研究报道了文库制备方法的一些重大进展。例如,在cDNA合成之前,对RNA进行片段化可以产生3ʹ:5ʹ偏倚,链特异性文库制备方法能够更好的区分正义链与反义链,这些改进都能够对转录本丰度进行更准确的估计。RNA片段化和链特异性文的制备很快就成了RNA-seq文库制备试剂盒中的标准方法。这里我们简要描述了其它RNA-seq方法的改良,使用这些改进方法的可以让研究者们根据他们的生物学问题以及特定样本进行选择。这些改进的方法包括在选择RNA进行测序时,取代dligo-dT富集的替代方法,或者是那些专门选择转录本的3ʹ或5ʹ末端的方法,或者是使用UMIs进行区分技术重复和生物重复的方法,以及针对RNA易降解特性改良的文库制备方法。这些方法的组合可以使研究者们阐明由可变poly(A)(alternative poly(A),APA),或替代启动子(alternative promoter)使用和可变剪接(alternative splicing)生成的复杂转录本。 Poly(A)富集的替代方法大多数发表的RNA-seq数据都是基于oligo-dT富集的mRNA方法,这种方法会选择包含poly(A)尾的转录本,并将集中测序测序那些在转录组的蛋白质编码区上。不过这种方法除了产生3ʹ偏倚外,RNA中还有许多非编码RNA,例如miRNA和增强子RNA,这些RNA不含有poly(A),因此不能使用这种方法进行研究。如果不进行poly(A)富集也无法达到目的,因为这会导至高达95%的读长来源于rRNA。因此,研究者们可以选择使用oligo-dT用于mRNA-seq,或者是剔除rRNA后进行WTA。短的非编码RNAs无法被oligo-dT方法捕获,使用WTA也很难对其进行研究,因此在研究非编码短RNA时需要特定的小RNA方法,这些方法主要是通过顺序RNA连接(sequential RNA ligation)实现的(通常小RNA建库试剂盒中就有相应的说明)。 WTA生成的RNA-seq数据来源于编码和一些非编码RNA。RNA的部分降解也能使用这种方法进行测序,RNA的降解会导至一些poly(A)从转录的末端分离。rRNA的去除有两种方法,一种是将rRNAs从其它RNA中剔除掉(所谓的pull-out法),另一种就是使用RNAse H酶来对rRNA进行降解。这两种方法都是使用序列特异性和物种特异性寡核苷酸探索来实现的,这些探针能与细胞质rRNA(5S rRNA,5.8S rRNA,18S rRNA和28S rRNA)和线粒体rRNA(12S rRNA和16S rRNA)互补。为了简化人类,大鼠,小鼠或细菌(16S和23S rRNA)样本的处理,通常将预先混合的寡核苷酸添加到RNA中,然后让它们与rRNA进行杂交,以便进行下一步的清除。其它高丰度的转录本,例如珠蛋白(globin)或线粒体RNA也可以按照类似的方法去除。pull-out方法结合了生物素化的探针和链霉素包裹的磁珠,它们可以用于除去寡聚的rRNA复合物,留下剩余的RNA用于建库例如Ribo-Zero(Illumina,USA)和RiboMinus(Thermo Fisher,USA)。RNase H酶降解法可以降低那些生成的loigo-DNA:RNA复合物,例如,NEBNext RNA depletion(NEB,USA)和RiboErase(Kapa Biossystems,USA)。最近对这些方法的比较说明,在高质量的RNA中,这两种方法都可以将rRNA降低至后续RNA-seq读长的20%以下。但是,作者说明了,RNase H方法比pull-out法的稳定性要强,并且比较不同试剂盒时,最后得到的DGE长度的偏倚比较明显。作者还描述了另外一种类似于RNase H的方法,这种方法表现不错,并且以前没有报道过。ZapR方法是Takara Bio的一项专有技术,它使用一种酶来降解RNA-seq文中的rRNA片段。rRNA剔除方法的一个局限是,相比对oligo-dT RNA测序方法,rRNA剔除方法需要更高的测序深度,主要是因为里面还会存有一定的rRNA。 Oligo-dT和rRNA剔除法都可以用于后续实验的DGE分析,研究者们可能会默认使用以前在他们的实验室中使用的方法或最容易使用的方法。然而,对于这些方法的使用应该考虑一些因素,尤其是那些易降解的样本,另外,WTA方法会检测到更多的转录本,但是其实验成本要高于oligo-dT方法。 富集的RNA 3ʹ末端用于Tag RNA-seq以及可变多聚腺苷酸分析(Enriching RNA 3ʹends for Tag RNA- seq and alternative polyadenylation analysis.)标准的短读长Illumina方法需要对每个样本生成1000万到3000万条(10M到30M条)读长用于高质量的DGE分析。对于那些专注于基因水平表达,并从事大型或高度重复实验的研究者们,或资源受限的研究者来说,可以选择使用3ʹtag计数。由于测序集中在转录本的3ʹ末端,因此需要的读长(reads)更少,这就降低了成本,并且一次测序的样本数目也可以更多。富集的3ʹ末端也可以用于确定单个转录本的poly(A)位点,而由于mRNA前体上存在的APA,其3‘末端可能会发生变化。(群主批注:目前单细胞转录组商业王者10X就是采用这种方法,仅仅是对3ʹ末端测序)
3ʹ mRNA-seq方法会产生每个转录本的单个标签读长(tag read),这些读长来源于3ʹ末端,这个标签(tag)丰度与转录本的丰度是成正比的。标签测序法(tag-sequencing protocols),例如QuantSeq(Lexogen, Austria)通常比标准RNA-seq法流程更为简单。标签测序法已经进行了优化,这种方法使随机引物或锚定的oligo-dT-primed来进行cDNA合成,从而并不需要poly(A)富集这一步骤,并在cDNA合成后立即进行PCR,从而取代了接头连接步骤。这种方法可以在低测序深度上实现与标准RNA-seq类似的灵敏度水平,因此,这种方法可以使用多路复用的形式实现多个文库的同步测序。这种建库方法的数据分析也进行了简化,因为不需要外显子连接检测和基因长度测序读长的归一化。但是,3ʹ mRNA-seq方法可能会被受到转录本同聚区(homopolymeric regions0的影响,这会导至错误标签;这种方法只能提供非常有限的异构体分析,这就会抵消它们较低测序深度带来的任何成本收益,尤其是对于那些仅够一次使用的样本来说。 mRNAs的APA化会产生3ʹ UTR长度不等的异构体。对于一个特定的基因来说,它不仅产生了这个基因的多个亚型,而且由于3ʹUTR中存在着顺式调控元件,这也会影响该转录本的调控。这种方法可以使用那些研究APA的研究者们更详细地研究miRNA的调控作用,mRNA的稳定和定位,以及mRNA的翻译。APA法指在富集转录本的3ʹ末端,从而提升信号与灵敏度,而前面提到的标签测序法非常适合此目的。其它方法多聚腺苷酸位点测序(polyadenylation site sequencing,PAS-seq),这种方法可以将mRNA打断为150bp左右的片段,并且使用oligo-dT标记的模板转换来生成cDNA用于测序,其中的80%读长就来源于3ʹUTR。TAIL-seq方法能不使用oligo-dT,在对RNA进行打断之前,这种方法会剔除rRNA,并将3ʹ-RNA接头连到的poly(A)的尾部。当片段化后,再加上5ʹ-RNA接头就完成了RNA-seq文库的制备。在RNA-蛋白分析方法中也能评估APA,例如紫外交联免疫沉淀(cross- linking immunoprecipitation, CLIP)测序。 富集的RNA 5ʹ末端用于起始位点回贴(Enriching RNA 5ʹends for transcription start- site mapping)使用富集7-甲基鸟苷5ʹ加帽RNA(7-methylguanosine 5ʹ-capped RNA)也可以进行DGE分析,这种方法可以用来鉴定启动子和转录起始位点(TSSs)。现存有几种方法都可以实现这个目的,但是这些方法很少作为常规手段来进行使用。在对基因表达的加帽分析(CAGE, cap analysis of gene expression),以及用于基因表达分析的启动子的RNA注释和定位(RAMPAGE, RNA annotation and mapping of promoters for analysis of gene expression)分析中,当使用随机引物生成第一链cDNA后,mRNA 5ʹ的帽子结构就被生物素化,这就可以将5ʹ cDNA通过链霉亲和素进行富集。CAGE使用II型限制性内切酶来生成短的cDNA标签,这种酶会从5ʹ端的接头下游切割21-27p的核核苷酸。相比之下,RAMPAGE操作则使用模板转换(template switching)来生成较长的cDNA,这个cDNAs随后被富集起来,用于测序。单细胞标签逆转录测序技术(single-cell-tagged reverse transcription sequencing, STRT-seq)能够在单细胞水平上实现TSS的回贴(mapping)。STRT-seq技术使用生物素化的模板转换oligos来生成cDNA,被磁珠捕获后,就在5ʹ末端进行片段化,产生短的cDNA标签。作为CAGE基础的5ʹ末端的加帽技术是由日本理化所(Riken)开发的,这种技术用于早期功能基因组学实验中,使全长cDNA克隆数量最大化。日本理化所主导的小鼠功能注释(FANTOM, Functional Annotation of the Mouse)协会通过阐明了1300多个人类和小鼠原代细胞,组织和细胞系的TSS,这充分显示了CAGE的强大。在最近一些方法比较中,CAGE也表示不俗。但是作者却报道说,仅使用5ʹ末端测序产生的假阳性TSS峰也是最多的,他们建议使用正交方法进一步来确认阳性,例如DNase I的回贴或H3K4me3染色质免疫沉淀测序(ChIP-seq)。 使用唯一分子标识符来检测PCR重复RNA-seq数据通常具有较高的重复率(duplication rates),也就是说许多测序读长会回贴到转录组的相同位置。与全基因组测序不同的是,在全基因组测序中,重复的读长被以认为是PCR这一步中出现的技术偏倚导至的,它会被移除,而在RNA-seq中,这些重复的读长则被认为是真正的生物学信号并被保留。在一个样本中,数百万个起始RNA分子也许代表了高表达的转录本,当对cDNA进行测序时,就会发现很多片段是相同的。因此,在比对(alignment)过程中,并不建议通过计算去除那些不必要的重复,因为这些重复中很多是真正的生物信号。当使用单端测序(single-end sequencing)时更是如此,因为一对片段中只要一端相同,就可以被认为是一个重复(duplicate),至于双端测序(paired-end sequencing),两端必须在同一位置时才能被认为是一个重复,但这种情况很少。但是,由于PCR偏倚,在制备cDNA文库时,还会存在着某种程度上技术重复,并且PCR复制偏倚是一种质控问题,它有可能对RNA-seq实验结果造成影响时,很难区分出这些技术重复与生物重复的程度。 现在已经提到将UMIs作为一种解释扩增偏倚的方法。在扩增前将随机UMIs添加到cDNA分子中,使得能够确认PCR重复,并且可以在后续的数据分析中将其除去,同时保护真正的生物学重复,从而改善基因表达的量化和等位基因频率估计的效果。当一对测序读长被确认为一个技术重复时,它们应该包括相同的UMI,并且被回贴到转录组中相同的位置(一端或两端,这取决于使用的是单端测序还是双端测序)。 UMIs已经被证明能够降低变异和错误发现率来提升RNA-seq中的DGE数据分析,并且这种方法在单细胞数据分析方面也有着重要作用,单细胞数据中的扩增偏倚可能更为严重。当试图在RNA-seq数据中进行变异检测(variant calling)时,UMIs也非常有用。虽然高表达的转录本可以产生适合这种变异检测的高覆盖率,尤其是包含了了这种重复时,但UMIs可以用于去他可能导至第二位基因频率错误计算的扩增假象。UMIs正在成为单细胞RNA-seq(scRNA-seq)的文库制备试剂盒中的标准,同时它也日益频繁地用于常规RNA-seq。 提高降解RNA的分析RNA-seq文库制备方法的发展也改进了低质量或降解RNA的分析,例如从临床相关获得的那些用福尔马林固定石蜡包埋(FFPE)块存储的样本中的RNA。低质量的RNA会导至不均匀的基因覆盖率,更高的DGE假阳性率和更高的重复率,它们与文库的复杂性呈负相关。但是,文库的制备方法已经被改良,改良后的方法能降低RNA降解的影响。这些方法可能在基于RNA-seq的诊断技术的发展中显得尤为重要,例如将来有可能出现的类似于OncotypeDX(目前并不是测序分析)的诊断,这种试剂盒基于21个基因RNA的标签来预测乳腺癌的复发。虽然现在有几种方法可以使用,但是比较后发现两种方法表现最好,即RNase H与RNA exome。我们前面提到,RNase H法使用核酸本科来降低RNA:DNA复合物中的rRNA,但是它却能阻止mRNA的降解。RNA exome方法使用类似于外显子测序(exome sequencing)那样的方法,使用寡核苷酸探针来捕获RNA-seq文库分子。这两种方法都能通过减少rRNA,同时不影响mRNA的手段来产生高质量和高度一致的基因表达数据。3ʹ末端标记测序技术与扩增子测序(在PCR扩增中能产生超过2万个外显子扩增子)方法也可以用于分析降低的RNA,但是这两种方法并没有RNase H方法使用广泛。 设计更好的RNA-seq实验仔细设计DGE RNA-seq实验对于获取高质量和生物意义数据有着非常重要的意义。尤其是要考虑到复制的层次,测序深度以及单端还是双端测序。 重复与实验功效(replication and experimental power)在一个实验中,足够的生物学重复(biological replicates)能够捕获不同样本之间的生物学变异;在定量分析中的置信度依赖于测序深度与读长长度。虽然RNA-seq比芯片表现了更低的技术偏倚,但是生物系统中固有的随机变化都要求任何RNA-seq实验要做生物学重复。使用额外的重复能够确定异常样本,在必要情况下,在进行生物学分析之前,移除这些异常样本或降低这些异常样本的权重。确定生物学重复需要考虑几个因素,包括效应大小(effect size),组内变异,可接受的假阳性和假阴性阈值,以及最大样本数目,有的时候还需要RNA-seq实验设计工具或功效(power)计算工具的辅助。 在一个实验中要想确定一个合适的生物学重复并非是一件简单的事情。一项48个重复的酵母研究表明,当使用3个生物学重复时,计算样本用于DGE分析的工具只能检测出20-40%的差异表达基因。研究表明,至少应该使用6个生物学重复,这个数量要超过文献中常用的3到4个生物重复的数量。最近的一项研究表明,4个生物学重复可能足够的,但是研究指出,在确定合适的重复数目之前,需要做一个预实验来确定生物样本的方差。对于高度多样化的样本,例如来自癌症患者肿瘤的临床组织,可能需要更多的重复,以便能以更高的置信度来确定基因的变化。 确定合适的读取深度(Determining the optimal read depth)一旦文制备好,就需要决定对它们进行多深的测序。读取深度指的是,每个样本获得的测序读长的目标数目。对于真核基因组中的常规RNA-seq DGE分析来说,一般认为每个样本需要100万-300万条读长(也就是我们常说的10M到30M数量)。但是,在多个物种中的实验结果显示当每个样本的测序读长数量为1M时,那么这个数量级的测序读长提供的转录本丰度信息与转录组中表达最高表达量的一半的转录本30M测序提供的丰度信息类似。如果实验的重点是关注那些最高表达相对较大变化的基因,并且如果有足够的生物学重复,那么就可以使用较低深度的测序就能解决驱动实验的假设。测序完成后,通过检查读长在样本之间的分布以及检查饱和曲线就能评估进一步的测序能够增加实验的灵敏度。随着测序通量的增加,为了控制技术偏倚,可以将一个实验的所有样本都添加一个“混合”文库中进行测序,这已经成了标准做法。一次测序所需要读长总数则是样本数乘以读取深度;然后根据生成所需的读长总数来对这个混合文库进行多次测序。这种合并需要严格检测每个样本RNA-seq |

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号