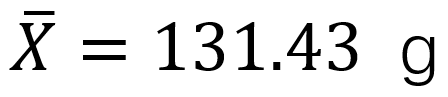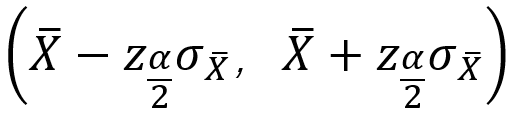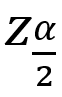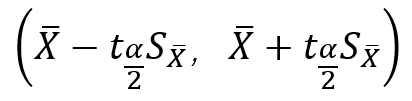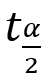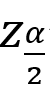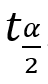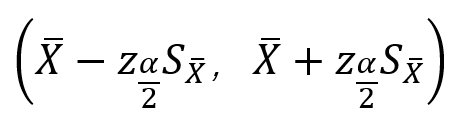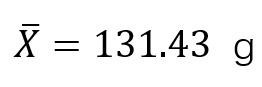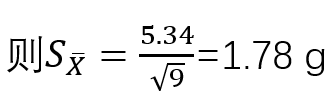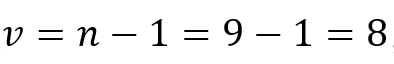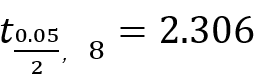在《数据收集与统计》中已经讲过,统计分析包括统计描述和统计推断两部分。上文中通过介绍统计图/表和描述数据分布特征的基本统计量(集中趋势的描述和离散趋势的描述),对统计描述进行了介绍。在了解了统计描述之后,本文将对统计推断进中的参数估计行简单介绍。 在日常工作中常常需要根据手中的数据,分析或推断数据反映的本质规律。即根据样本数据如何选择统计量去推断总体的分布或数字特征等。统计推断是数理统计研究的核心问题。所谓统计推断是指根据样本对总体分布或分布的数字特征等作出合理的推断。它是统计推断的一种基本形式,是数理统计学的一个重要分支。 统计推断包括两个重要内容: 参数估计(parameter estimation)和假设检验(hypothesis testing)。参数估计是指用样本指标值(统计量)来推断总体指标值(参数)。在已知系统模型结构时,用系统的输入和输出数据计算系统模型参数的过程。18世纪末德国数学家C.F.高斯首先提出参数估计的方法,他用最小二乘法计算天体运行的轨道。20世纪60年代,随着电子计算机的普及,参数估计有了飞速的发展。 参数估计包括点估计(point estimation)和区间估计(interval estimation)两种方法。点估计就是用相应样本统计量直接作为其总体参数的估计值。通常它们是总体的某个特征值,如数学期望、方差和相关系数等。点估计问题就是要构造一个只依赖于样本的量,作为未知参数或未知参数的函数的估计值。 构造点估计常用的方法包括:矩估计法、最大似然估计法、最小二乘法、贝叶斯估计法。区间估计是按预先给定的概率(1-α)所确定的包含未知总体参数的一个范围。是依据抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,作为总体分布的未知参数或参数的函数的真值所在范围的估计。例如人们常说的有百分之多少的把握保证某值在某个范围内,即是区间估计的最简单的应用。 点估计 正如前文所说,总体均数的点估计是直接用随机样本的样本均数作为总体均数μ的点估计值。例如,某批原料的重量值是一个总体,但我们不可能对该原料所有的个体都进行重量的测量,因此总体的参数μ—平均重量值未知。 为此,随机抽取该批次原料9个,根据《数据收集与统计》中的方法,计算其平均重量
标准差S=5.34g,这两个均为样本统计量。若用样本均数X作为总体均数μ的一个估计,用样本的标准差S作为总体标准差的一个估计,即认为该批原料的平均重量为131.43g,标准差为5.34g。这就是点估计。 在这个问题中,总体参数μ是未知的,但他是固定的值,并不是随机变量;而样本统计量是随机的,不同的样本所得到的结果是不同的。 如果随机抽取的原料为另外9个,其重量的均值和标准差就会是另外一个值,如果以此作为整批原料重量的点估计,其结果也是正确的。因此,由于点估计方法计算简单,但未考虑抽样误差,受抽样个数及个体影响,要考虑抽样误差。 区间估计 总体均数的区间估计是按一定的概率(1-α)用一个区间范围来估计总体均数,这个范围称为可信度为(1-α)的可信区间(confidence interval,CI)又称置信区间;预先给定的概率1-α称为可信度或置信度(confidence level),常取95%或99%,如没有特别说明,一般取双侧95%。可信区间通常由两个数值,即可信限/置信限(confidence limit,CL)构成。其中较小的值称可信下限(lower limit,L),较大的值称可信上限(upper limit,U),一般表示为L~U。 总体均数可信区间的理论基础是样本均数的抽样分布规律。总体均数可信区间的计算方法,随总体偏差σ是否已知,以及样本含量n的大小而异。下面将总体均数可信区间的计算方法进行简单介绍。 ① 如果总体标准差σ已知,根据标准正态分布的原理,总体均数的可信度为(1-α)的可信区间为
其中,
为双侧尾部面积为α的Z界值。 ② 如果总体标准差σ未知,根据t分布的原理,总体均数的可信度为(1-α)的可信区间为
其中
为自由度是v,双侧尾部面积为α的t界值 ③总体标准差σ未知,但n足够大时,t分布近似标准正态分布,可用标准正态分布代替t分布,即用
代替②中的
此时对总体均数的可信度为(1-α)的可信区间进行近似计算
还是刚才的例子,随机抽取某批次原料9个称重,其平均重量
标准差S=5.34g。
其自由度
α取双侧0.05,查表克制t界值表得
按照②中的公式,可得出(131.43-2.306×1.79,131.43+2.306×1.79)即(127.30,135.56)g即该批次原料单个重量均数的95%可信区间为(127.30,135.56)g。 下面对可信区间作进一步的说明 1、可信区间的含义: 在区间估计中,总体参数虽然未知,但其值却是固定的值,而不是随机变量值,其大小与抽样无关。可信度为95%的可信区间的含义是:如果重复100次抽样,且这100次抽样中样本含量相同,每个样本均按同一方法构建95%的可信区间,则理论上平均有95个可信区间包含了总体均数,还有5个可信区间包含未包含总体均数。 从正态总体随机抽取的100个样本中,可计算100个样本均数及标准差和100个总体均数的可信区间。当(1-α)=95%时,在计算的100个可信区间中,有95%个可信区间包含了总体均数,而另外5个不包括。 因此,95%的可信区间不能理解为:总体参数有95%的可能落在该区间内,更不能理解为:有95%的总体参数在该区间内,而5%的参数不再该区间内,因为相应的总体参数虽然未知,但是却存在,且只有一个。而所谓95%的可信度指的是可信区间的构建方法,理论上用该方法建立的95%可信区间能包含总体参数的概率为95%。 在实际工作中,只能根据一次试验结果估计可信区间,如上述例子中的95%的可信区间为(127.30,135.56)g,就认为该区间包含了总体均数μ。根据小概率事件不大可能在一次试验中发生的原理,该结论(该区间没有包含总体均数μ)错误的概率小于等于0.05%。 2、可信区间估算的优劣 可信区间估计的优劣取决于两个要素。第一个要素是准确性,又称可靠性,反应为可信度1-α的大小,显然可信的越接近1越好。准确性要根据研究目的和实际问题的背景由负责人自行决定,常用的可信度为90%,95%和99%,但并不以此为限。第二个要素是估计精确性,常用可信区间的长度CU-CL衡量。其长度越小越好。 精确性和个体变量的变异度大小、样本量和1-α取值有关。当1-α确定后,可信区间的长度受制于个体变异和样本含量,个体变异越大,区间越宽;样本含量越小,区间越宽。 当样本含量确定后,准确性和精确性是相互牵制的,若要提高可信度,取较小的α值,此时势必使区间变长,精确性下降。因此,不能笼统地认为99%的可信区间比95%的可信区间好。实际工作中,一般常用95%可信区间,认为他能较好地兼顾准确性和精确性。 |

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号